I. Introduction
Dementia is a brain disorder that affects more than 35 million people worldwide, compromising their ability to perform basic activities [1]. Projected increases in the number of dementia patients will strain health-care systems [2]. Personal assistive technologies are viewed as a promising means of supporting dementia sufferers.
KASPAR is a proof-of-concept assistive technology designed to provide personal health-care services to dementia patients. KASPAR verbally guides a patient through a picture description task, a task commonly utilized in the assessment of dementia patients. KASPAR engages the user in description of the "Boston Cookie Theft" picture [3] depicted in Figure 1.
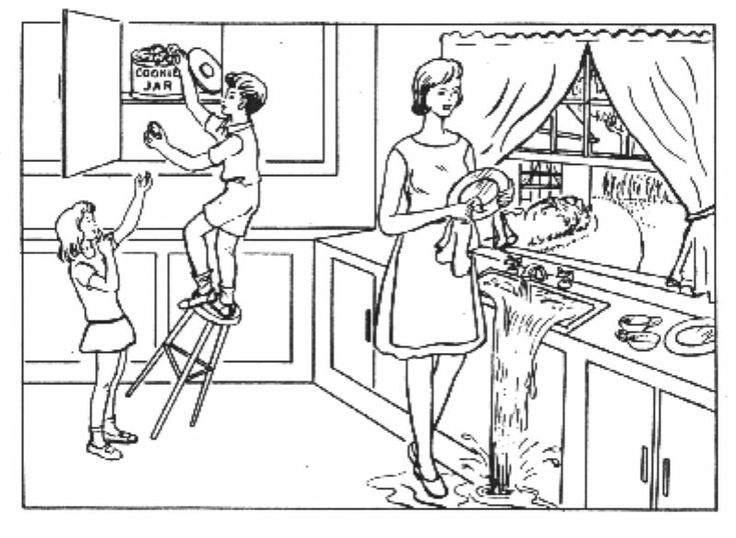
II. System Design
The components of the KASPAR system are depicted in Figure 2. KASPAR is designed to be customizable to a particular patient and task. Thus, specifics of the patient, task, and session are stored in knowledge bases which are accessed by other modules of the system. KASPAR is currently embodied in a robot augmented with an external microphone and laptop computer.
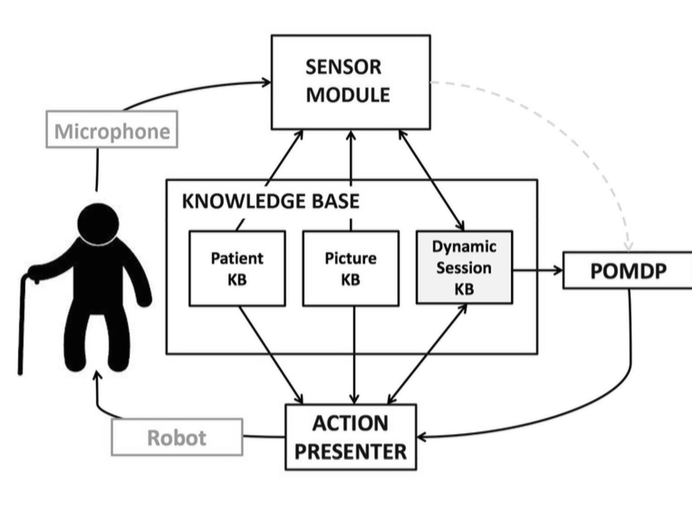
KASPAR utilizes three knowledge bases:
Knowledge Base - Picture (Picture KB)
The Picture KB records the objects and relations in the picture. It is described in OWL DL, which is a language for authoring ontologies [4]. Two major benefits of using the ontological knowledge base are:
Making the decision-making process generalizable. To change the domain of the task, just plug in a different Picture KB.
Allowing connections to commonsense ontologies like OpenCyc and WordNet and conducting formal reasoning.
Knowledge Base - Patient (Patient KB)
The Patient KB stores patient information such as name or age as key-value pairs – this information is used to customize the contents of a conversation.
Knowledge Base - Session (Session KB)
The Session KB stores the status of the conversation: objects and relations mentioned, expected responses from the user, emotional estimations about the user, etc. It serves as the communication medium of the system - all other modules read from and write to the session KB.
Sensor Module (SM)
The Sensor Module has two primary functions: i) collecting input, and ii) processing it.
Audio input is collected using a microphone. We use Microsoft’s System.Speech to detect and segment audio speech into utterances.
Though strong at detecting speech, System.Speech performs poorly in transcribing the audio into text, so Google’s Web Speech is used for speech recognition. We pass the audio signal to Web Speech when System.Speech indicates speech is present and collect the transcript from Web Speech when System.Speech indicates speech has ended.
Order-preserving matching of keywords and phrases is used to find objects and relations in the text. Using the information in the session KB, the SM determines if new objects or relations have been mentioned, if these objects or relations are mandatory for the task, and if the user has correctly answered a question, when applicable. The SM also extracts lexical features to estimate confusion using a model built from a database of conversations with dementia patients.
Partially Observable Markov Decision Process (POMDP)
POMDPs provide a mathematical framework for modeling decision processes under uncertainty where action effects can be non-deterministic and states are partially observable; the true state of the world is mapped to observations with known probabilities [5]. A probability distribution over the state of the world is maintained (the belief state), and is used for choosing the optimal action to perform at each time step t.
We model our problem as a POMDP since the cognitive state of the patient is not directly observable. Moreover, the audio input is noisy, which introduces further uncertainty. The goal of our POMDP module is to choose the optimal action to perform based on its belief of the current cognitive state of the patient. For this application, actions are either general classes of speech, or adjustments to the mode of speech including volume and speech rate. These action outputs are sent to the Action Presenter which generates the actual dialog. Termination of the conversation is reached when either:
the user has successfully described most of the pre-determined mandatory objects and relations in the picture, or
the user was unsuccessful in describing the picture despite repeated prompts by KASPAR
Solving a POMDP with a large state-space is computationally intractable, which poses a significant challenge. Our work focuses on developing a POMDP model that is robust in guiding the patient towards completion of the task, and yet solvable within a reasonable amount of time. We use symbolicPerseus, a point-based value iteration algorithm for solving POMDPs, as our primary POMDP solver. Implementation details of symbolicPerseus can be found in the PhD thesis of [6].
Action Presenter (AP)
The Action Presenter carries out the actions determined by the POMDP as speech.
Speech synthesis follows verbal strategies commonly used by caregivers assisting individuals with Alzheimer’s disease. Such strategies include: giving one proposition per utterance, using encouraging comments, and calling the patients by name [7].
When the POMDP decides on an action, the AP will search the session KB for relevant information and then generate an appropriate response. For example, when the POMDP asks the AP to prompt an open-ended question about an object and the patient has just mentioned the object "boy", the AP may generate the speech "Good job. What else can you say about the boy?" Such sentences are generated using manually-tuned templates.
III. Future Work
Sensor Module
With video input, it may be possible to: estimate emotion from facial expressions; resolve pronoun ambiguity with eye- or hand-tracking (for example, "She is next to her" may be accompanied by gestures towards the subject and object).
Methods to gain semantic understanding of utterances can be used to recognize objects or relations.
POMDP
Hand-coding the objectives of the POMDP module becomes infeasible with a large state-space. We are interested in techniques for automating the process.
Knowledge Base
The patient profile can be augmented with common sense and medical ontology frameworks to generate more sophisticated dialog. Ontology learning techniques can also be utilized to enrich the profile of a given patient as the conversation progresses.
Action Presenter
Besides verbal communications, the AP should be able to perform gestures and facial expressions with guided strategies.
Acknowledgements
The work reported here was a joint project with Sheila McIlraith, Frank Rudzicz, Hamidreza Chinaei, Alberto Camacho, and Hoda Zare. We also gratefully acknowledge funding from the Natural Sciences and Engineering Research Council of Canada (NSERC) Undergraduate Student Research Awards program.
References
[1] S. Gauthier, M. Panisset, J. Nalbantoglu, and J. Poirier, "Alzheimer’s disease: Current knowledge, management and research," Canadian Medical Association Journal, vol. 157, no. 8, pp. 1047–1052, 1997.
[2] A. Mihailidis, J. N. Boger, T. Craig, and J. Hoey, "The cOACH prompting system to assist older adults with dementia through handwashing: An efficacy study," BMC geriatrics, vol. 8, no. 1, p. 28, 2008.
[3] H. Goodglass and E. Kaplan, Boston diagnostic aphasia examination booklet. Lea & Febiger Philadelphia, PA, 1983.
[4] D. L. McGuinness, F. Van Harmelen, and others, "OWL web ontology language overview," W3C recommendation, vol. 10, no. 10, p. 2004, 2004.
[5] H. Geffner and B. Bonet, "A concise introduction to models and methods for automated planning," Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 8, no. 1, pp. 1–141, 2013.
[6] P. Poupart, "Exploiting structure to efficiently solve large scale partially observable markov decision processes," PhD thesis, University of Toronto, 2005.
[7] R. Wilson, E. Rochon, A. Mihailidis, and C. Leonard, "Examining success of communication strategies used by formal caregivers assisting individuals with alzheimer’s disease during an activity of daily living," Journal of Speech, Language, and Hearing Research, vol. 55, no. 2, pp. 328–341, 2012.