Introduction
Video data, such as movies, consists of multi-source media and is a rich source of information. The complex features in video data are difficult, but interesting, to analyze. Due to the significant advances in the field of computer vision, we can now effectively track people and label their actions in videos [5]. Recent work has started to tackle a high-level semantic understanding of videos such as reasoning about the plot, mood and motivation of the characters in movies [8, 6].
The goal of our work is to identify characters in movies. Character identification plays an important role in the semantic understanding of stories [5]. For example, in order to understand a movie plot, one first needs to know who everyone is in every scene. In this paper, we focus on training a Siamese convolutional neural network (CNN) model for character identification in the MovieQA dataset [6]. In particular, our method scores each face track in a movie against a set of images of actors playing the main characters using a Siamese CNN.
Approach
In this paper, we aim to identify faces in movies from the MovieQA dataset which aims to evaluate automatic story comprehension [6]. We extracted each movie’s cast list and actors’ photos from IMDb, an online resource for movies (http://www.imdb.com/). Since actor photos typically contain the full person, we first performed face detection on each image, which is explained in more detail in Sec. 2.1. We cropped an image of the face from each detection. Our goal was to compare images in each face track to face crops from actors photos, and assign the most similar actor to each face track. In this abstract, we implement a Siamese convolutional neural network to solve the face identification problem, which we describe in Sec. 2.2. Finally, we explain how we apply our Siamese convolutional neural network to our movie data in Sec. 2.3.
Face Detection in IMDb data
We employ Xiangxin Zhu’s face detector [7] to perform face detection on the photos extracted from IMDb. Zhu’s algorithm detects facial landmarks using probabilistic models based on the concept of mixture of trees [7]. It was trained on the annotated facial landmarks in the wild (AFLW) data set [2].
Zhu’s algorithm achieved good results on the IMDb data. However, the algorithm could occasionally make small mistakes like missing small faces or faces in oblique poses (poor performing examples are shown in Figure 3). We lowered the default threshold to allow more detections through. This aimed to ensure that each face was detected, but could result in false positives. To deal with this, we built a face/non-face classifier using more powerful features. In particular, we used a CNN with the architecture from [3].
We trained the classifier on the AFLW data set. The AFLW data set contains many facial images and their corresponding bounding boxes. We wanted to generate some data with face/non-face labels. Therefore, we made random crops from the original AFLW’s images. These were labeled as positive face examples if their intersection over union (IOU) with the original bounding box was higher than 75%, and we labeled those with IOU under 25% as non-faces. We then employed the trained CNN network on face detections from the IMDb data. Figure 4 contains some examples of our combined models’ results.
Siamese network for Face Verification
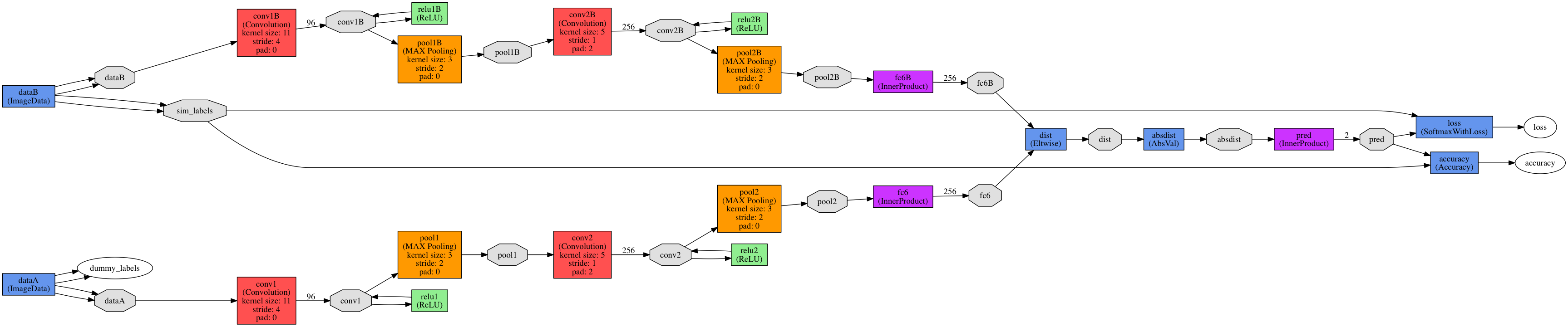
Figure 1: The architecture of our Siamese CNN used for the task of face verification.
Neural networks have became a hot topic due to their impressive success in various fields and applications such as image search, speech recognition, and language understanding. CNNs are a type of neural network with local connectivity properties and efficient parameter sharing achieved by their use of convolutions. They are particularly well suited for image-related tasks.
Traditional CNNs are often used in classification problems; in our task, this would mean classifying each image (in a face track) as one of the actors in the database. However, building a simple classification CNN might not be feasible for our task because it requires that all the classes be known in advance, and assumes many examples are available per class. In our setting, new actors can appear in every movie and each typically has only a few image examples. Thus, we used the idea behind face verification approaches that aim to take a pair of photos as input and predict whether they belong to the same person or not.
The specific architecture that we adopted was a Siamese network, which is often used in face verification challenges [4, 1]. This kind of network is commonly used where there is a large number of classes to train and/or not all examples have been seen during training [1]. The idea is to pass each of the two images, one from the face track and one from the actors’ database, through two CNNs which share all the parameters. The top layer features from the two streams typically go through another set of fully connected layers, finally solving our prediction task.
The Siamese network we built consists of two replicas of 2-conv-layer CNNs which are used to extract features from the two image inputs. Absolute difference of the features are passed to a fully connected layer which classifies inputs into two classes: match and mismatch pairs. Our network closely follows DeepFace’s [4] Siamese structure in which the weights are trained by the standard cross entropy loss and back-propagation of the error. We applied exponential decay to the learning rates and we also normalized the pixel values of images to be in the range [0,1]. The network’s structure is shown in Figure 1.
Face Identification in Movies
We applied a detector-based multi-pose face tracker @KnockMakarand on our movie data to get face tracks. The results are shown in Figure 2. The tracker performed well on our movie data. We also applied our Convolutional Neural Network from Sec. 2.2 to compare actors’ photos’ face detection results for IMDb images 2.1 to our movie face track in order to identify characters being tracked in each frame. We took the average score across all frames for each actor and selected the actor with the highest average score as the character identity for the face track.
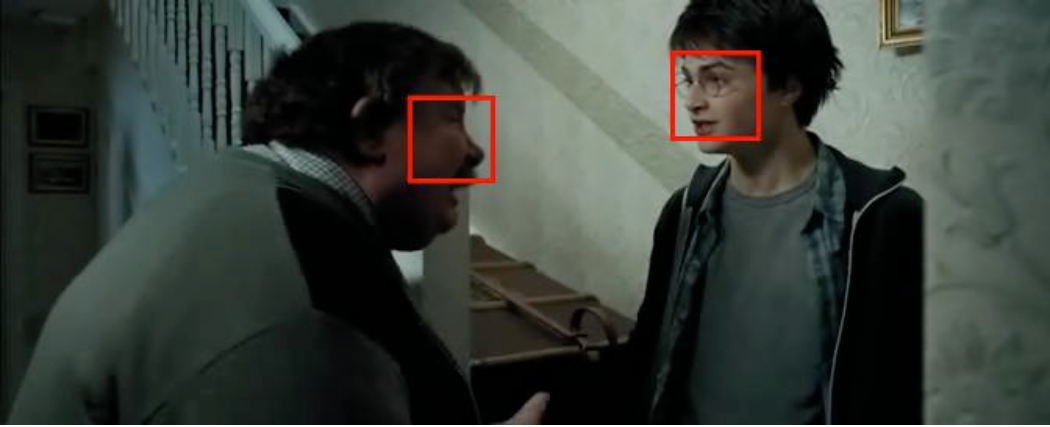

Figure 2: Applying the face tracker to movie data.
Analysis
In the following sections, we will discuss the major findings of our project and demonstrate some results along the way.
Face Detection
The face detection results on IMDb images are displayed in Figure 4. The method generally works well on single-face images, but performance fluctuates when there are multiple people in the images (shown in figure 3). Our face detection results improved significantly with the help of our CNN face/non-face classifier, reaching 91% accuracy, 90% recall and 92% precision rate on our test images.
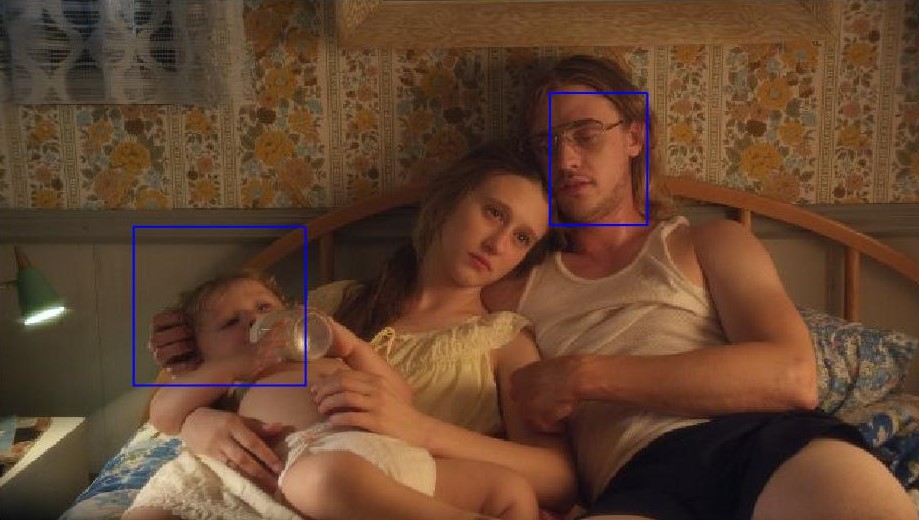

Figure 3: Poor performing examples of multi-face detection using Zhu's algorithm.


Figure 4: Examples of face detection on IMDB.
Siamese Network
The Siamese network we built takes a long time to train. It is still in the progress of training.
Conclusion and Future Work
We have introduced a method for identifying characters in movie data. We are now building the Siamese convolutional neural network model which would be used with actors’ photos extracted from IMDb to identify characters in movies. The model is slowly coming together.
There are many directions we can pursue to create a better model for face identification in movie data. One possible direction would be to investigate a better loss function for our Siamese network. Another direction is that we can take advantage in the richness of the information in video data to help us improve our current model’s performance. There is quite a bit of useful information from the movie data that we did not explicitly model, including actor’s costumes, audio tracks, and subtitles. Integrating these factors should make the model more robust. Currently, our algorithm only gives similarity scores between a pair of face images. However, we are using temporal data - videos. An interesting future project may be to implement an algorithm that provides similarity scores in face tracks.
Acknowledgement
I would like to express my deepest gratitude to my supervisor, Sanja Fidler, and my mentor, Lluis Castrejon, for their excellent guidance and support on every stage of this project. This work was supported by NSERC Undergraduate Student Research Awards. I would also like to thank Makarand Tapaswi for his face detection results on the MovieQA dataset. Finally, I want to express my appreciation to Yukun Zhu and Zhihao Luo for offering me much help.
References
-
Sumit Chopra, Raia Hadsell, and Yann LeCunn. Learning a similarity metric discriminatively, with application to face verification. In IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2005.
-
Martin Koestinger, Paul Wohlhart, Peter M. Roth, and Horst Bischof. Annotatedfacial landmarks in the wild: A large-scale, real-world database for faciallandmark localization. In First IEEE International Workshop on BenchmarkingFacial Image Analysis Technologies, 2011.
-
Alex Krizhevsky and Geoffrey Hinton. Convolutional deep belief networks oncifar-10. In Unpublished manuscript 40, 2010.
-
Yaniv Taigman, Ming Yang, MarcAurelio Ranzato, and Lior Wolf. Deepface: Closing the gap to human-level performance in face verification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
-
Makarand Tapaswi, Martin Bauml, and Rainer Stiefelhagen. knock! knock! who is it? probabilistic person identification in tv-series. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
-
Makarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, RaquelUrtasun, and Sanja Fidler. Movieqa: Understanding stories in movies through question-answering. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
-
Xiangxin Zhu and Deva Ramanan.Face detection, pose estimation, and landmark localization in the wild. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
-
Yukun Zhu, Ryan Kiros, Richard Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In ICCV, 2015.