1 Introduction
Version control is a system of recording changes to a codebase over time in the form of commits so that specific versions and commits can be recalled later. A commit represents the difference between two versions of the source code. Version control systems are currently used broadly in software development. However, understanding the functional changes brought about by a given commit can be challenging. For instance, it is often necessary to determine the set of requisite commits for implementation of a feature or bug-fix. This forces developers to comb through commits and interpret the respective commit messages manually. This problem arises when a developer submits a feature for code review. It is naturally desirable to submit only the commits that are related to the feature while leaving out the irrelevant ones. We previously developed two $history slicing tools$, namely DEFINER [1] and CSLICER [2] to solve this problem. These tools help developers save time by automating the process. The programs however do not possess powerful graphical user interfaces (UI) and can only be operated through the command line, rendering them difficult to use. In order to unify the tools and make them more accessible, a web application was created. Through this application, users can easily access the tools without having to learn proper commands to run them in a command line environment.
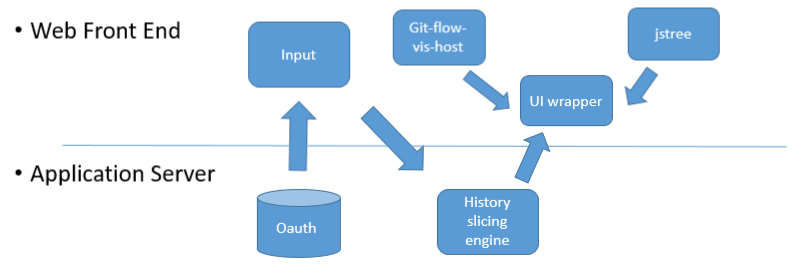
Figure 1: Architecture Diagram
2 Approach
Several libraries, tools, and technologies were utilized to build this web app. Figure 1 shows how they are connected to each other. It also presents the relationship between back-end and front-end components. The app’s core, however, consisted solely of DEFINER and CSLICER. The inputs to our tools are a Git repository, a history range (a continuous sequence of commits), and a set of test cases. A typical usage of the tool involves the following steps:
-
The Git repository’s name and access permission are obtained by asking the users to log into their GitHub accounts. Users are redirected to the login page of GitHub using the OAuth framework [3], an authorization protocol. An authorization form is then displayed, indicating the type of permissions being granted. Next, users are asked to select the intended repositories from a list of all available options (See Figure 2).

Figure 2: Repositories’ names
-
A node.js library called “git-flow-vis-host” [4] is used to facilitate the process of selecting a history range. This library helps us visualize the history of the selected repository and allows the users to select a history range. The visualized history is a diagram containing relevant information such as commit IDs and log messages (see Figure 3). Users indicate the start and the end of a range by clicking on two commits. The resulting history range comprises the start and end commits, as well as every commit in between.

Figure 3: Tests and history of a repository.
-
The last step is to select test cases. A JavaScript library, “JsTree” [5], is used to display the test classes as well as the associated tests in a tree structure (see Figure 3). We analyze compiled byte code of the repository and extract all available test cases. Users then select the intended tests by clicking on a class and its $respective$ test cases. The test cases are used to determine whether a commit is related to a feature or high-level functionality. For example, to find the commits related to a $feature$, developers can select its associated feature test.
The selected history range is then divided into several subsets. In the initial state of the execution, the division happens randomly. Subsequently, each test case is executed on all the resulting subsets. In the case of a test failing, it can be concluded that the subset is missing at least one related commit. Based on the test failures, commits are given a score and subsequent subsets are generated using the given scores. If all the tests pass, the subset is guaranteed to contain all the necessary commits. This subset can then be used as a new history range. This process is repeated until deriving a minimal set of commits that pass the tests, i.e., removing any of the commits in the subset results in a test failure. Finally, the web app highlights the commits in the selected subset that are required for tests to pass (See Figure 4).
Figure 4: The final result is highlighted.
3 Analysis
We evaluated our tool on an open source software project Apache Commons-csv [6] , which is a Java library for manipulating CSV files. The evaluation task was to identify the commits that preserve a feature called “IgnoreCaseHeaderMapping”. The targeted history range was from the start commit, b230a6f5, to the end commit, ffb3c493, which contains 78 commits. The test case used is called “testIgnoreCaseHeaderMapping”, which is a method in the “CSVParserTest” class. It took our app a few minutes to display the result. The result consists of ten commits. Closer examination made it clear that applying those commits preserves the target feature. Since we were not familiar with the code and change histories of the project, it would have taken us a few hours to identify these ten commits. In addition, the current slicing engine executes tests sequentially and it can be slow when the input history is long.
4 Conclusion
In this paper we shared our experience developing a web app to reach our goal of facilitating the use of our original tools, DEFINER [1] and CSLICER [2]. We explained how the web app works and what techniques and libraries we used to improve the quality of user experience. In the future, the goal is to optimize DEFINER [1], by multi-threading it to run the test in parallel instead of sequentially, and the web app, by implementing a cache of previous results. We believe parallelization will improve the performance of DEFINER. We hope to store the results for each run in cache and reuse them in subsequent runs.
Reference
- Yi Li, Chenguang Zhu, Julia Rubin and Marsha Chechik. Precise Semantic History Slicing through Dynamic Delta Refinement. In Proc. of 31st IEEE/ACM Int. Conf. on Automated Software Engineering (ASE’16).
- Yi Li, Julia Rubin and Marsha Chechik. Semantic Slicing of Software Version Histories. In Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering, ASE 2015.
- OAuth - https://oauth.net
- Teun/git-flow-vis-host - https://github.com/Teun/git-flow-vis-host
- JsTree - https://www.jstree.com/
- Commons-csv - https://github.com/apache/commons-csv